公司新闻
Adam该换了!斯坦福最新Sophia优化器,比Adam快2倍,几行代码即可实现!
首发:AINLPer微信公众号(获取分享干货!!)
编辑: ShuYini
校稿: ShuYini
时间: 2023-05-26
大模型的预训练成本巨大,优化算法的改进可以加快模型的训练时间并减少训练开销。目前大模型的训练优化器基本上都采用Adam及其变体,并且Adam的应用已经有9个年头了,在模型优化方面相当于霸主的地位。但是能否够在优化器方面提高模型预训练效率呢?今天给大家分享的这篇文章是来自斯坦福的最新研究成果,他们提出了「一种叫Sophia的优化器,相比Adam,它在LLM上能够快2倍,可以大幅降低训练成本」。

Paper:https://arxiv.org/abs/2305.14342
随着参数规模的增长,语言模型(LLM)获得了惊人的能力。然而,由于数据集和模型规模庞大,预训练LLMs非常耗时,一般需要对模型参数进行数十万次更新。例如,Google的PaLM在6144个TPU上训练了两个月,耗资1000万美元。因此,「预训练效率是扩大LLM的主要瓶颈」。这项工作旨在通过更快的优化器提高预训练效率,从而减少实现相同预训练损失的时间和成本,或者以相同的预算实现更好的预训练损失。
在大模型的预训练过程,主要用到的优化器就是Adam及其变体。例如GPT、OPT、Gopher和LLAMA。「为LLM预训练设计更快的优化器具有挑战性」。首先,对于Adam中一阶(基于梯度的)预调节器的好处当前并没有一个很好的解释。其次,预调节器的选择受到限制,因为我们只能提供轻量级选项,其开销可以通过迭代次数的加速来抵消。例如K-FAC中的块对角线 Hessian 预调节器对于LLM来说过于昂贵。另一方面,在基于轻量级梯度的预调节器中自动搜索并识别Lion,在视觉Transformer和扩散模型上比Adam要快得多,但在LLM上的加速效果是有限的。
为此本文介绍了一种新的模型预训练优化器:Sophia(Second-order Clipped Stochastic Optimization),这是一种轻量级二阶优化器,它使用Hessian对角线的廉价随机估计作为预调节器,并通过限幅机制来控制最坏情况下的更新大小。在GPT-2等预训练语言模型上,Sophia以比Adam少了50%的步骤,且实现了相同的预训练损失。**由于Sophia几乎每步的内存和平均时间都保持在50%的Adam步骤,因此也就可以说其在总的时间上面也减少了50%**。如下图所示:
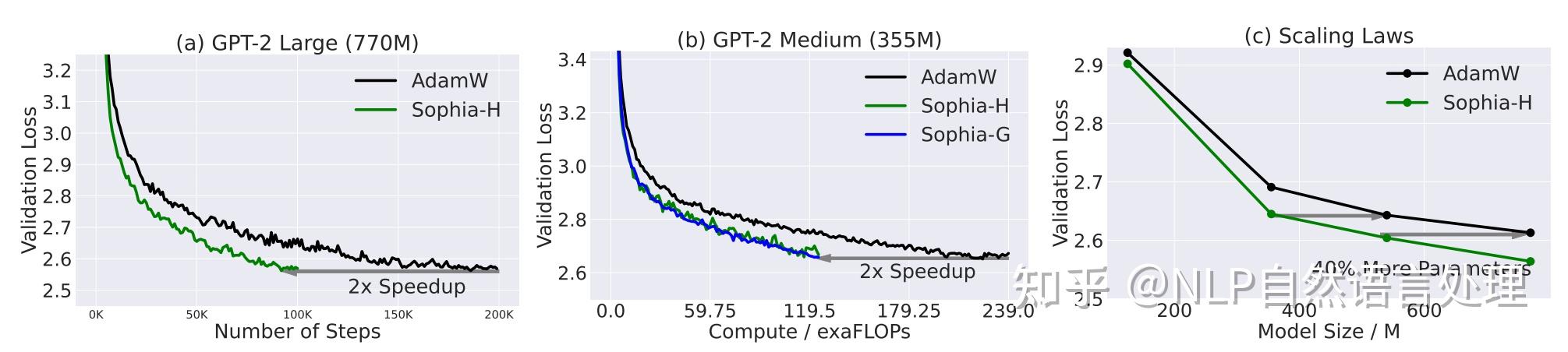
此外,基于模型尺寸从125M到770M的缩放规律是Sophia优于Adam,随着模型尺寸的增加,在100K步长时,Sophia与Adam之间的差距越来越大(上图C所示)。特别是,Sophia在一个540M参数、100K步的模型上给出的验证损失与Adam在一个770M参数、100K步的模型上给出的验证损失相同。请注意,后一种模型需要多40%的训练时间和多40%的推理成本。
具体来说,「Sophia每k步使用一小批示例来估计损失的Hessian矩阵的对角线条目(本文实现中k=10)」。本文考虑了对角Hessian估计器的两种选择:(a) 使用Hessian向量积的无偏估计器,其运行时间与mini-batch梯度达到一个常数因子相同;(b)有偏估计器,利用重采样标签进行小批量梯度计算。这两个估算器每步(平均)仅引入5%的开销。在每一步,Sophia都会用梯度的指数移动平均值(EMA)除以对角Hessian估计的EMA,然后用标量进行裁剪来更新参数。具体算法如下图所示:

此外,「Sophia可以无缝集成到现有的训练Pipeline中,对模型架构或计算基础设施没有任何特殊要求」。对于任意一种Hessian估计器,Sophia只需要标准的小批量梯度,目前主流的PyTorch、JAX等深度学习框架都可以支持Hessian矢量的应用。
「得益于基于hessian的预调节器,Sophia比Adam更有效地适应了不同参数尺寸的非均匀曲率」,而这种非均匀曲率经常发生在LLS损失的情况下,并导致模型训练不稳定或减速。Sophia具有比Adam更激进的预调节器:相比平坦维度(Hessian较小),Sophia对尖锐维度(Hessian较大)的更新具有更强的惩罚力度,以确保所有参数维度的损失均匀减少。相比之下,Adam的更新在所有参数维度上基本一致,导致平面维度的损失减少较慢,这些使得Sophia可以在更少的迭代中收敛。下面是个Toy例子:
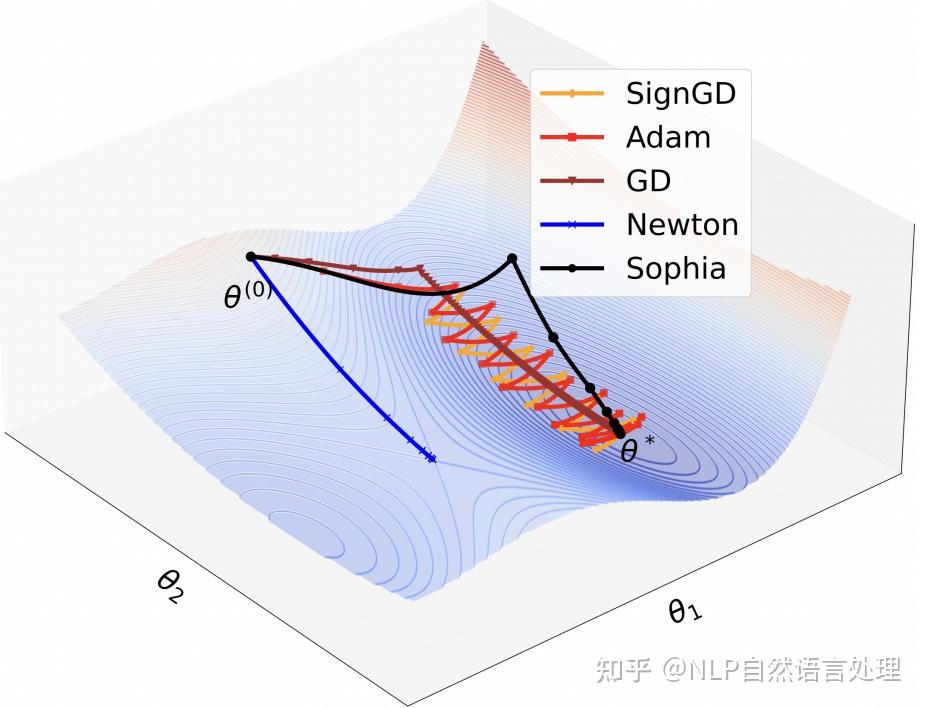
其中:是尖锐维度,
是平坦维度。GD 的学习率受限于
的锐度,并沿着
缓慢前进。Adam和SignGD沿着
反弹,同时沿着
缓慢前进。Vanilla Newton 的方法收敛到一个鞍点。Sophia在两个维度上都进步很快,几步就收敛到最小值。
「Sophia的机制控制了所有方向上最坏情况下更新的大小」,以防止Hessian估计不准确、Hessian随时间快速变化和非凸曲线的负面影响。这种控制机制可以让我们并不需要随机的频繁估计Hessian。相比之下,先前的二阶方法通常每一步都会更新Hessian估计。
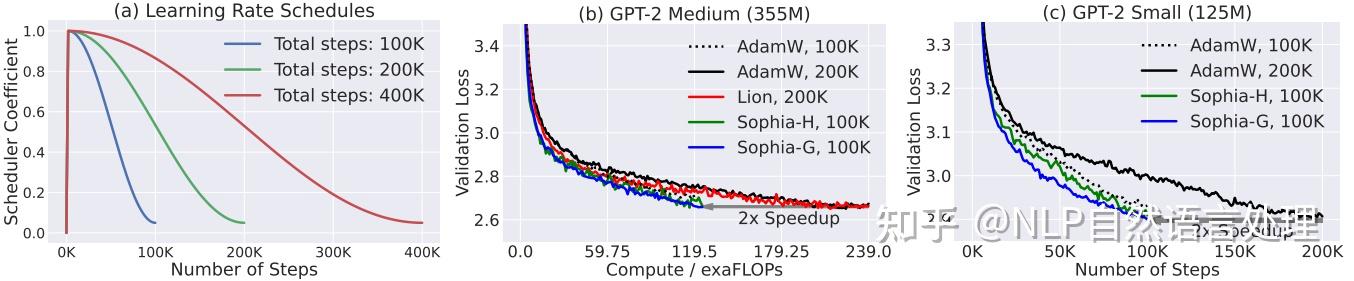
下图展示了,基于在OpenWebText,具有相同步数(100K)的验证损失曲线。Sophia始终比AdamW和Lion具有更好的验证损失。随着模型规模的增长,Sophia 和基线之间的差距也越来越大。

具有相同的100K步骤情况下,如上图C所示:Sophia-H在770M模型上实现了0.05更小的验证损失。这是一项重大改进,因为根据该制度中的 scaling laws和下图中的结果,0.05损失的改进相当于实现相同验证损失的步骤数或总计算量的2倍改进。
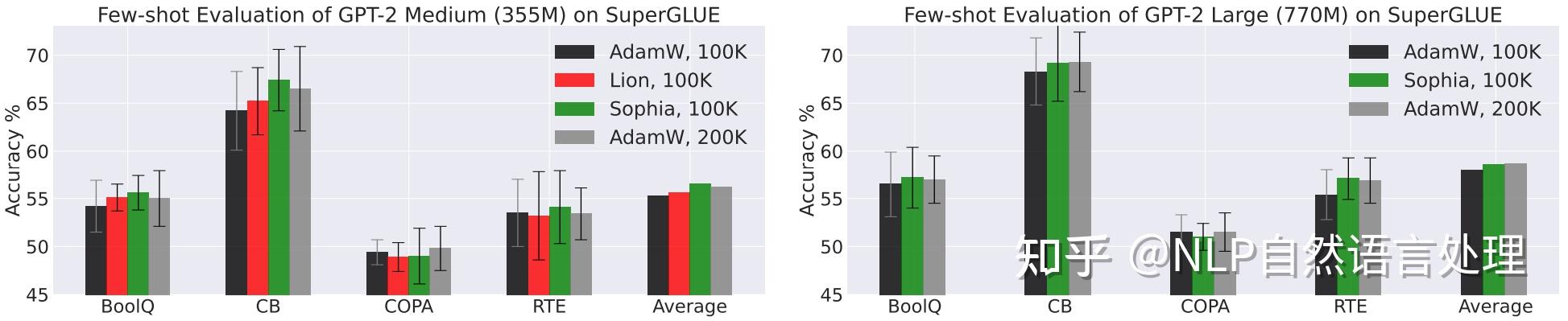
对SuperGLUE的Few-shot评价,如下图所示(绿色代表Sophia)。「相同的100K步,使用Sophia预训练的模型在大多数任务上优于使用AdamW和Lion预训练的模型」。使用Sophia预训练100K步的模型与使用AdamW预训练200K步的模型具有相当的性能。
[1]QLoRA:一种高效LLMs微调方法-48G内存可调65B!
[2]斯坦福发布AlpacaFarm,RLHF人工成本降低45倍!
万泰新闻中心
联系我们
公司名称: 万泰-万泰平台-万泰中国加盟站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

